
Protect your intellectual property by running GenAI models locally
This is a continuation of my previous blog post on running open source models locally. In this blog we add Open WebUI as a web interface to provide the end user similar experience as ChatGPT.
Following is a short summary of why run local models locally.
Why Run Open-Source GenAI Models Locally?
Running open-source GenAI models locally provides several benefits:
- Data Protection: Keep sensitive information within your organization’s control. By processing data locally, you can keep sensitive information from leaving your organization’s premises, reducing the risk of data breaches and intellectual property theft.
- Increased Control: With full control over the deployment environment, you can tailor the setup to meet your specific requirements, ensuring that your models are used as intended.
- Improved Performance: Running GenAI models locally allows for faster processing times and reduced latency, making them more suitable for real-time applications.
- Enhance Security: Reduce the risk of data breaches and intellectual property theft by processing data locally.
Open Source License Requirements
Please check the licensing requirements for the open source model you are going to use as it may be quite different depending upon the model you use. The license may also be different depending on the type of use (personal, educational, commercial, etc.)
Step-by-Step Process
Follow these three simple steps to install and run multiple LLMs locally.
Step 1: Set up Ollama
Ollama is an open source project that enables you to run large language models (LLMs) locally without going through too much hassle. It is available at GItHub (see references below)
Open terminal window on Macbook and use the following commands:
mkdir llmcd llmcurl -L https://ollama.com/download/ollama-darwin-arm64 -o ./ollamachmod u+x ollama ./ollamaStep 2: Download LLM model you want to run
Go to a new terminal windows and pull llama3
./ollama pull llama3Step 3: Run the Model
Once the model is downloaded, you can run it and use prompts on the command line. Following is a typical session with one prompt and its response:
./ollama run llama3Step 4: Install Open WebUI
Use the following steps to install Open WebUI.
python3 -m venv venv . venv/bin/activate pip install open-webuiThe first line creates a new Python environment. The second line activates this environment and the third line installs Open WebUI.
Step 5: Run Open WebUI
Use the following command to run Open WebUI.
open-webui serveYou will see a bunch of messages appear on the terminal window as shows in the screenshot below.
Now point your web browser to http://0.0.0.0:8080 or http://localhost:8080 where you have to create an account the first time you use Open WebUI. You are ready to ask questions using this web interface. On the top-left corner of the following screenshot, select one of the installed models from step 2 and then enter prompt for that model.
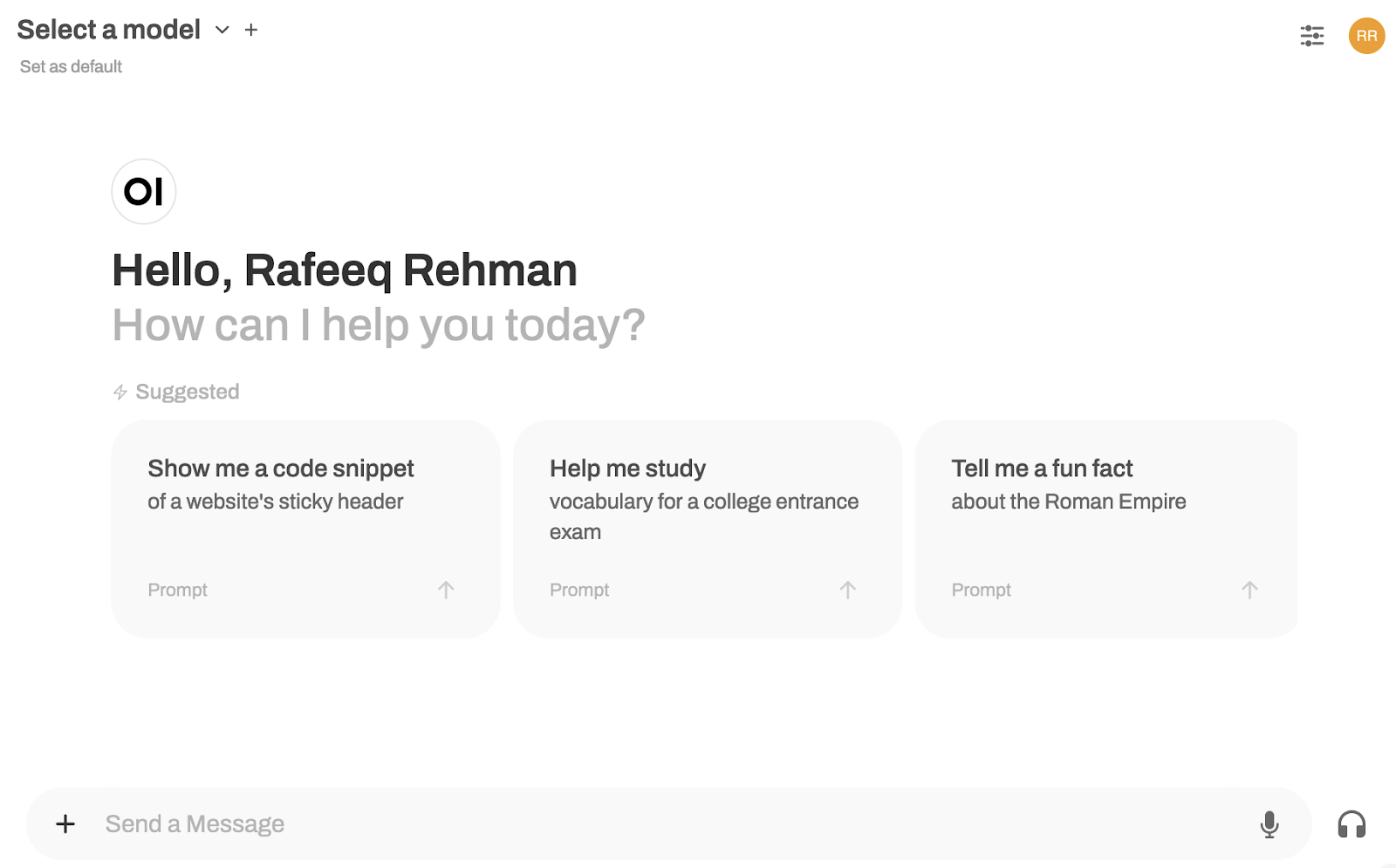
If you have multiple models installed locally, you can use the same prompt to check how they respond differently.
References
- https://github.com/ollama
- https://github.com/ollama/ollama
- https://ollama.com/library
- https://docs.openwebui.com
Subscribe to Blog
Subscribe to blog to get email notification of new posts